 Embeddings are the way modern language models translate sentences into a numeric space. How to interpret them remains, I think, a very complex subject that is still under significant research.
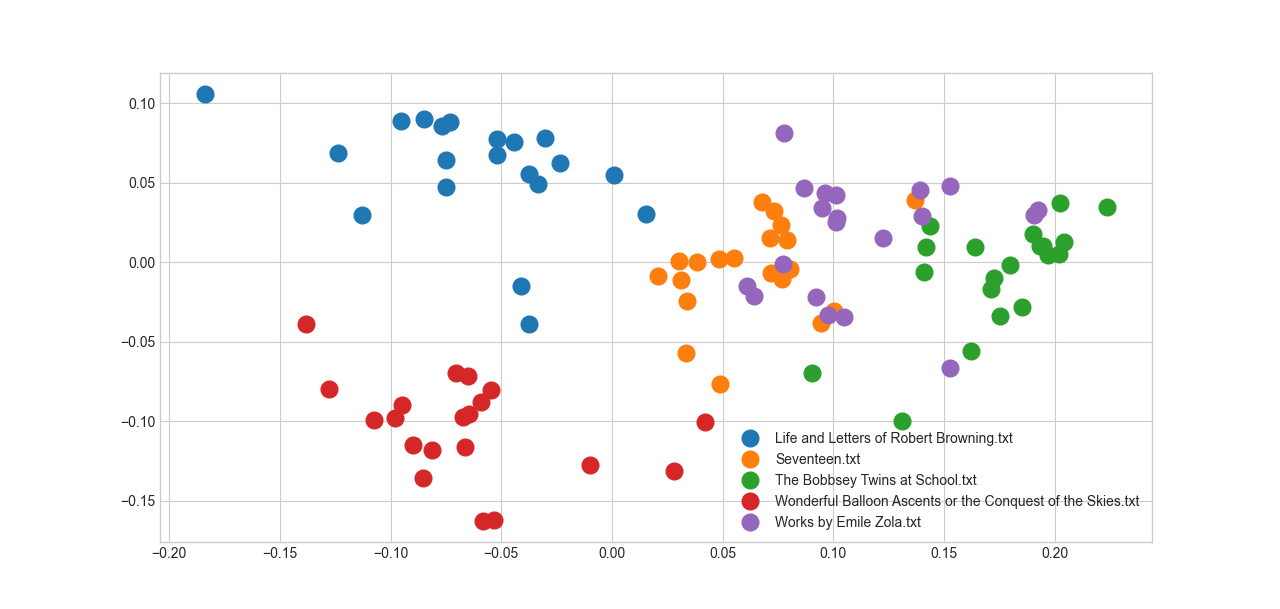
But their usefulness is indisputable. As a quick demonstration of that, I took a set of about 1000 full book texts from Project Gutenberg and extracted lines of text from each. I then computed the embedding of each line of text to get a numeric representation of the content of the book. The result, after a bit of processing (averaging the embeddings, and performing a PCA to reduce it to a human-comprehensible two-dimensional) generates a map of a random selection of five of these 1000 books. What immediately caught my eye about this is how it cleanly separates the books from each other. Life and Letter of Robert Browning is to the top left, Wonderful Balloon Ascents to the bottom left, and so on. Part of this is undoubtedly subject matter–I doubt the Life and Letters of Mr. Browning is heavy on balloon-related material. But you can repeat this exercise even for books that are likely similar in terms of subject matter, for example novels from the same era, and you’ll achieve the same separation. The chart made me wonder how well embeddings can predict which book a given segment of text comes from. So I built a model to do just that. I took 50 segments of 5 lines of text from each book; each line contains about 5 words, so this amounts to only 25 words (a little bit longer than the average length of a sentence in English). Then I used a neural network model to predict which book those 25 words came from, based on the embedding of those 25 words. Remarkably, even with only 25 words, I was able to get about 20 percent accuracy. Considering that there are about a thousand books in the dataset, if you guessed randomly you’d only achieve an accuracy of about 0.1 percent, so this is about 200 times better. It’s pretty wild to me that a computer can identify a book out of a library of 1000 possibilities based on as little as a one-sentence sample from that book. The longer the segment I took from the book, the more accurate this model got. With 50 words, it was around 40 percent accurate; with about a paragraph of text (250 words) to draw on, it had about a coin flip’s chance of selecting the right book. Whatever the embeddings are, they act like a fingerprint of what book they come from. The model does even better at predicting authorship. The Project Gutenberg sample I have mostly features single authors, but there are also some who are present dozens of times, like Stephen King or Robert Louis Stephenson or William Makepeace Thackeray. The most frequent author is Thackeray, whose books make up about 4 percent of the total sample. That forms a baseline for our accuracy: if you just guessed Thackeray for everything, you’d be right 4 percent of the time. The model does much better than that, achieving a remarkable 40 percent accuracy with single-sentence excerpts transformed into embeddings. I can’t stress enough that the model doesn’t have access to the raw text here, only its transformed form–as a list of numbers. To guess authorship with that level of resolution, only a single sentence or two, boggles my mind. How does this compare to the state of the art? I’m not an expert, but I found this dissertation with a nice, clear methods section from which I could do an apples-to-apples comparison. In the dissertation, they built a set of 50 authors and used 1000 word training sets, using convention methods based on word frequency and hand-constructed features. These methods look at things like sentence length, the use of different types of words (parts of speech, etc.), and how often each word is used in an author’s texts. I copied the basics of their methodology, pulling out 50 distinct authors and 20 segments of 1000 words each to build the embeddings from. I was able to achieve an accuracy of 78 percent with such large segments and relatively fewer authors. Better still, my F1 score came to 0.72, which would be the best of any method or model they looked at for assigning authorship in their dissertation (by a good margin, too). It’s interesting that the embeddings are able to capture something about the style of each author here. I used to think of them as measuring semantic similarity, that is the meaning of the sentences they’re computed from, but I don’t think that’s correct. They’re actually wrapping up style and substance into one list of numbers, which might be why semantic measures don’t fully align with them. At a broader level, I think this goes to show why “AI,” even though it’s kind of a bullshit marketing term, is also a big fuckin’ deal. With just a little bit of work and off-the-shelf embeddings, I could easily beat the best pre-AI models. Those models were powered by years of humans sitting down and carefully thinking about what aspects of text differed between authors and how to separate them, before developing numeric approximations to those qualities. The model I used wasn’t even designed for authorship assignment and I downloaded and used it with just a few lines of Python code. The ability to rapidly distill text to numeric features–even though it’s not quite clear what those features mean!--is a game-changer for accelerating the development of Natural Language Processing (NLP) tools. Paradoxically, though we humans are excellent at thinking in text and, separately, very good at working with numbers, translating between them has been quite difficult. It’s still very early days though, and the performance of deep learning approaches hasn’t been matched by their interpretability. We can use them, but we don’t know why they work, and that’s a dangerous mixture.
0 Comments
Leave a Reply. |
 RSS Feed
RSS Feed